谁才是最强的视频动作识别算法?
· 朱毅 Amazon Applied Scientist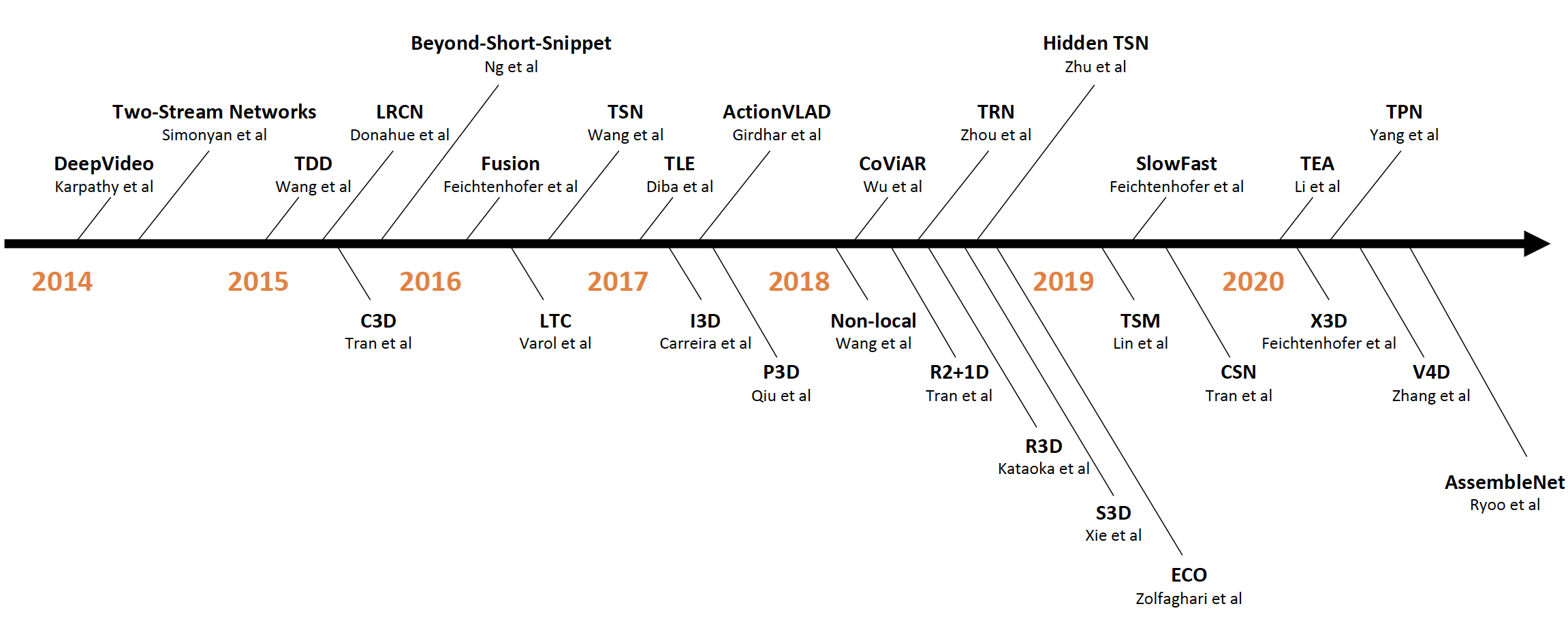
2020短视频继续爆发式发展,对视频理解的需求也继续猛增。不论是搞科研,还是项目落地,如何选择一个合适自己应用场景的视频模型至关重要。然而,论文满天飞,SOTA年年变,到底该怎样快速上车视频风口呢?在这次GluonCV 0.9.0发布中,我们不仅提供了针对视频动作识别可复现的模型库 (46个模型,支持PyTorch和MXNet),易上手的教程(特征抽取,模型微调,FLOPS计算),还有涵盖200+篇论文的综述,以及对应的视频教程(Youtube和bilibili)。不论你需要一个能复现的代码库,还是准确率最高的模型,还是公平比较的基准(包括数据集),或是未来研究的方向,GluonCV 0.9.0里都能找到,一应俱全。
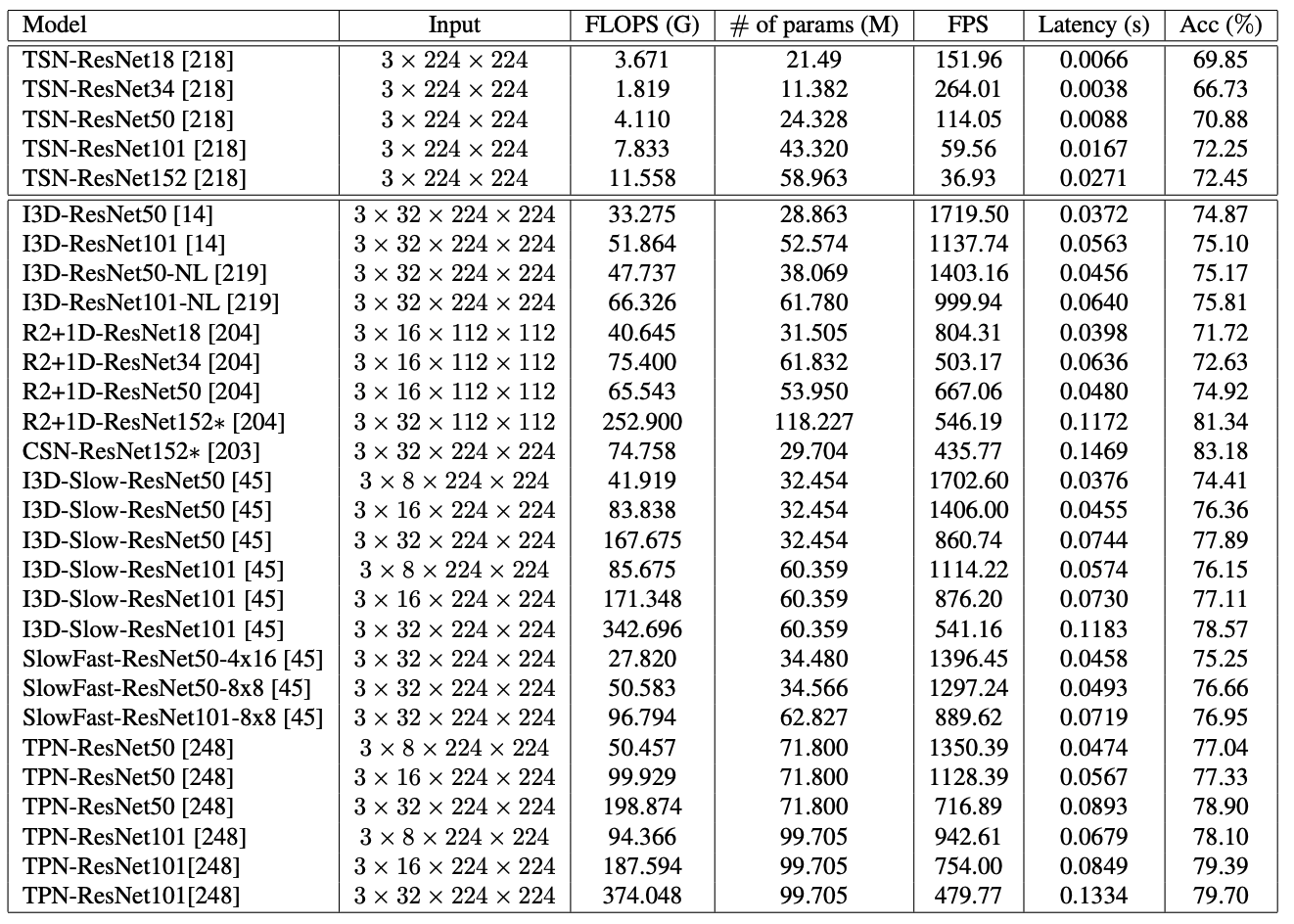
目前很多视频领域的数据集需要用户自行下载,而视频平台的管理与下载过程的网络波动都有可能使得每次下载的数据集不完全一致,进而导致不公平比较。因此,我们首先在统一的数据上复现了大量流行的视频动作识别算法(数据准备GluonCV也有提供)。如下表所示,我们逐一展示了每个模型的计算FLOPS,参数量的大小,每秒可处理的视频帧数,延迟时间以及在Kinetics400数据集上的准确率。我们发现尽管3D网络的精度比2D网络稍高,但也会带来更多的计算消耗,延迟大大增加。对效率要求很高的系统,比如边缘设备,或许2D网络更适合部署。另外,预训练数据集的大小往往比模型的改进能带来更多的精度提升,比如两年前的CSN模型在IG65M大型数据集的加持下,可以轻松超越最新的所有算法。所以我们的一个结论是,视频方向从业者可以考虑尽可能多搜集或者清理一些数据,比一味的追求最新最好的模型要实用的多。除此之外,针对不同的应用需求,我们也应该灵活选用不同的网络。比如对于较短的视频,我们就无需选用具备长时间跨度建模的模型。如果想了解更多模型的特性,请参考我们的综述论文。
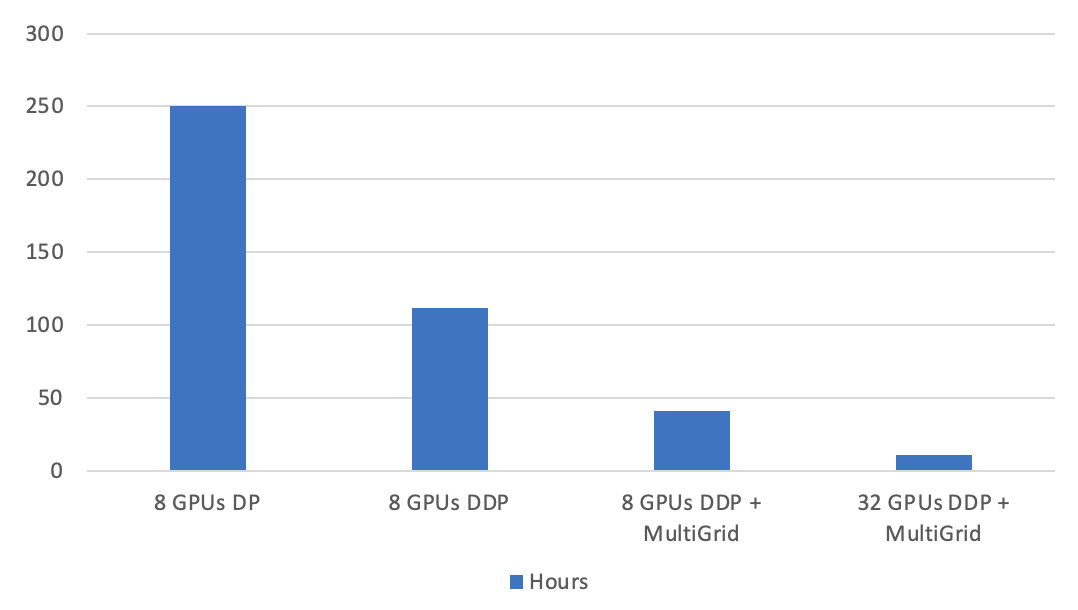
另外,训练一个SOTA的视频模型非常耗时耗力,即使在8卡V100的服务器上,动辄也要花费一周的时间。为了帮助大家快速迭代,我们提供了DistributedDataParallel (DDP)框架的支持和Multigrid训练方式。如下图所示, 在单机8卡的设置下,基线DataParallel (DP) 模式需要250小时完成I3D模型100个epoch的训练,我们的框架可以在41个小时内完成训练,比基线快6倍还不掉点。如果使用4个八卡V100的服务器,则可以在10小时内训练完毕,完美线性提速。相比而言,mmaction2基于视频输入的I3D在单机8卡上训练则需要148个小时。
总结
GluonCV 0.9.0提供了基于PyTorch的视频动作识别的模型库。从做好玩的demo,到有用的研究,到真正的落地,我们都有对应的配套教程。在接下来的发布中,我们还会陆续更新PyTorch的模型库,包括目标检测,目标跟踪,多模态视频学习以及自监督视频特征学习的模型。欢迎大家贡献自己的工作到GluonCV里来, 也欢迎给我们留issue开PR,感谢小伙伴们一直以来的支持!
相关链接
喜欢我们的工作并且希望支持更多的更新,欢迎点赞加星Fork!